Tag: data
-
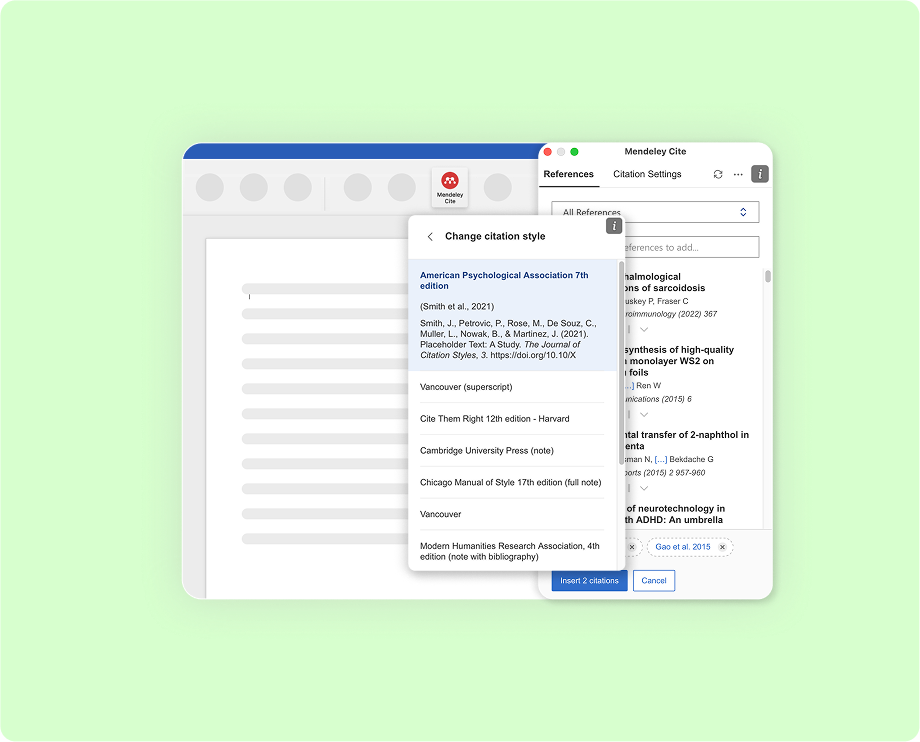
The Most Popular Citation Styles, Revealed!
Citations are incredibly important to a researcher’s workflow, as well as an author’s merit. The two more well-known kinds of citation formats are in-text citations and footnote citations. Not too long ago we announced the release of footnote citation styles in Mendeley Cite and while adding that feature, we realized that information about citation styles…
Written by
·
1–2 minutes -
Store, Share and Find: Manage It All with Mendeley Data
You recently learned about how Elsevier’s Mendeley Research Network can help you stay updated on the latest trends and developments in your field. But there’s another tool within Mendeley that can give you peace of mind about the data you’ve already generated in your research. Mendeley Data is a free, secure cloud-based repository where you…
Written by
·
3–5 minutes -

Mendeley Data awarded Data Seal of Approval
On June 22, it was announced that Mendeley Data’s open research data repository won the Data Seal of Approval certification; this award confirms that the repository complies with the Data Seal of Approval guidelines, and is a trusted digital repository. The 16 rigorous guidelines include guarantees to the “integrity and authenticity of the data” and…
Written by
·
1–2 minutes -
Mendeley at JCDL 2014
The Mendeley Data Science team have been busy attending some important events around the world. One of them has been JCDL 2014, the most prominent conference in the Digital Libraries arena. The conference looks at many of the problems we’re tackling at the moment, such as article recommendations and the best ways of automatically extracting…
Written by
·
2–3 minutes -
Discussing the Future of Recommender Systems at RecSys2014
Maya and Kris from the Mendeley Data Science team have just returned from RecSys2014, the most important conference in the Recommender System world. RecSys is remarkable in that it attracts an equal number of participants from industry and academia, many of whom are at the forefront of innovation in their fields. The team had a…
Written by
·
2–3 minutes